
In this information age, it is a deplorable state that despite the overload of information, we regularly fail to locate relevant information in a timely manner. This is mainly because of the misinterpretation of the context of the information, there may be some spam sites which contains irrelevant information the seeker will waste time in reading those sites.
The subject of this thesis is the design and implementation of a search service – Web Spam Detection, targeted at researchers to help them perform search tasks effectively for better results. The system contains major approaches like the browser with search engine, which helps in detecting spam sites.
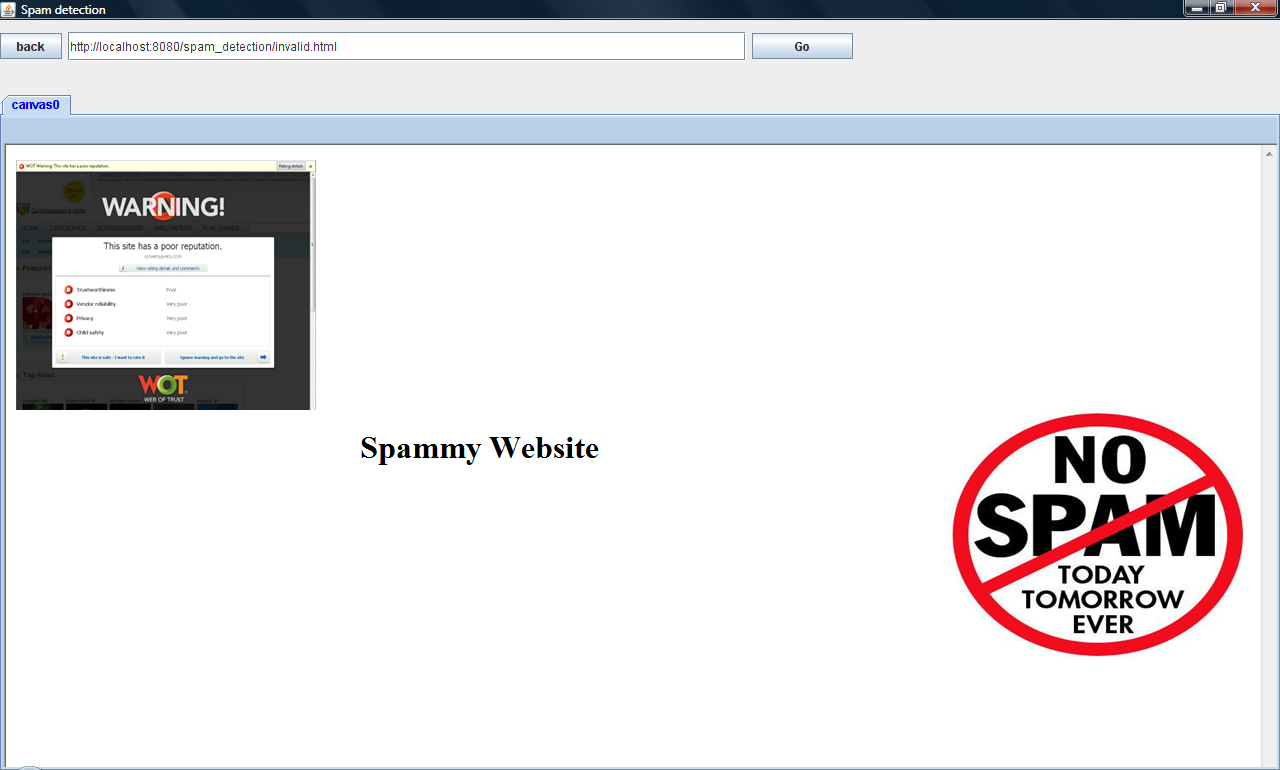
In the browser which we have developed, it does the same function as the real time browser and as soon as when the url is entered in the address bar of the browser, it will direct to our web service and checks whether it is spam or non-spam site. If spam website is identified by the url, then the user has been given a message that he/she have accessed an invalid url otherwise it loads the page normally.
So he/she does not need to read those irrelevant information. It checks the spam sites according to its characteristics. For the keyword entered in the search engine it uses KLD Classifier algorithm, to identify the spammy websites. KLD classifier looks for the term dependency between the query and linked page.
In this information age, online information resources are abundantly available and widely used. Particularly, in the field of academia, several Terabytes of academic content is uploaded on the Internet every week, and the demand for such resources is always on the rise.
Tragically, access to this information using a generic search engine is not satisfactory in terms of the relevance of links and the overtime on bad links.
This can be attributed to several factors, the most important being the absence of identification of context of the search which leads to spammy websites and lack of customization based on user’s profiles.
In an attempt to alleviate these issues, we present a search engine service surfing for any information available in the web. The motivation for this endeavor lies in the following assumptions and inferences.
URL Validation
Users can enter the url in the developed browser which can be identified that the entered url is valid or not. For the url entered by the user, the browser helps in displaying the web page and the entire source code have been crawled for detecting whether it is executing within the same requested server or not.
Search Engine Development
User can enter any keyword to search in the developed browser and the links can be displayed after crawling the source code. KLD classifier can be applied for the links which are irrelevant when the user clicks on those links suggesting us not to go to those spammy websites.
Relevancy and efficiency enhancement
Efficiency can be enhanced by displaying a message to the user before that spam page requested by the user is loaded. Using KLD classifier, our search engine reduces the overtime on bad links and improves relevancy. If the user’s action can be identified by any warning message, then the identification of the context of search can be highly accurate.
SCOPE OF THE PROJECT
- Provides an exclusive search service for general information from the web.
- Helps users by avoiding them in going to spammy websites.
- Makes the searching process easier by understanding the context of the search qiven as query.
- Helps in detecting the spam websites using the KLD Classifier by proceeding with a message to the user.
- Reduces the overtime on bad links.
OVERALL CONCLUSION
Web search engines provide a window to the ever expanding world of online academic content. In our web service we are preventing the user before getting into the spam sites. The search engine does this work internally that when the url or keyword entered it will extract the information and then it will display the relevant pages according to that particular one.
It will take a little amount of time to load the page but it is more convenient than the time spend in reading the spam sites. Although relevancy can be improved by precise calculation in the KLD classifier. The WSDA system that we propose attempts to achieve non-spam sites alone by identifying the spa sites and giving an alert to the user. Using this system, relevancy is considerably improved and the overtime on bad links reduced.
FUTURE WORK AND EXTENTIONS
In order to amplify the perceived quality and usefulness of the collaborative results, we have identified the following future directions to the system.
- While modeling the web service, if it is a non-spam sites it will give an alert after the user clicks on it but we have to enhance this before the page gets loaded.
- In terms of response time Java can be optimized for quicker querying and other faster options can be used for information extraction.
RESULTS AND DISCUSSIONS
RESULTS
When the user types a keyword in the search engine it will display the links and information according to that keyword and if the url entered on the browser it will display the results according to that as web page. When the user clicks on the particular link it will load the page if it is not a spam after it undergoes our system services.
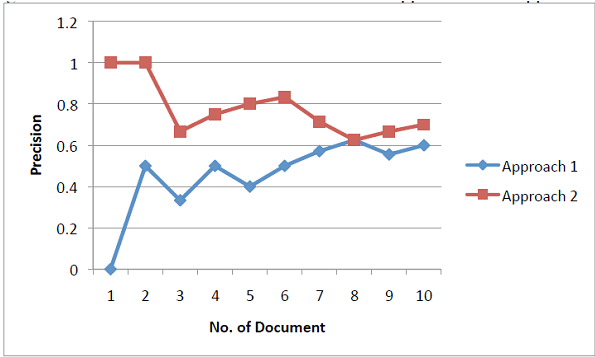
Precision values for both the approaches(Yahoo and WSDA) can be plotted in the graph below
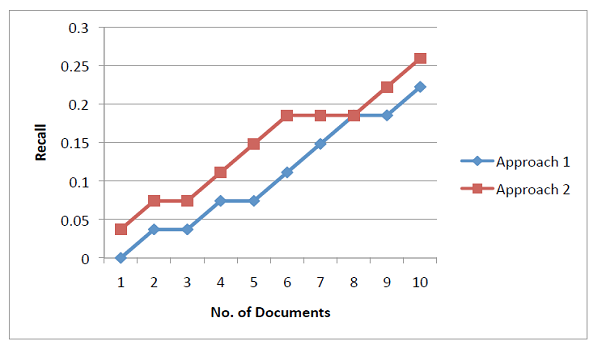
Recall values for both the approaches(Yahoo and WSDA) can be plotted in the graph below
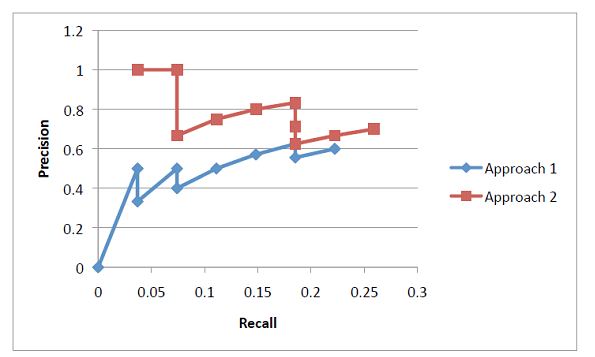
Now we plot the Precision-Recall graphs. The Precision-Recall graph for Approach 1 and 2 is shown in Figure 5.3
ANALYSIS
When the user clicks before loading the page it will check whether the given one is spam or non spam through the spam characteristics. Not only checks for the spam page it will check whether it belongs to the same domain or server, or not.
PROBLEMS AND ISSUES
Our system will extract the page source content and it will checks whether it is spam or not by doing KLD calculation. We also try to extract surrounding text for comparison.
hi can i get source code and documentation for this project?
*educational purposes only
thanks a lot
Hi can i get the source code as a guide fot my project
i m need for the source code for this project! Pls do try sending me
sir,
can i get the source code of this project .i need it urgently
Can i please get the documentation for this project. Thank you very much
can i plz get the source code?
Please share the source code and reports.
please send source code this topic
Web Spam Detection and Analysis Java Project
Can I get the source code of the web spam detection and analysis project pls?
Hi, Ms.Sharmila
If you got the code for this webspam detection and analysis project then pls send me the code
can you provide me the Web Spam Detection and Analysis Java Project source code and report
Thank you