ABSTRACT
The purpose of this Movie Success Rate Prediction project is to predict the success of any upcoming movie using Data Mining Tools. For this purpose, we have proposed a method that will analyze the cast and crew of the movie to find the success rate of the film using existing knowledge. Many factors like the cast (actors, actresses, directors, producers), budget, worldwide gross, and language will be considered for the algorithm to train and test the data. Two algorithms will be tested on our dataset and their accuracy will be checked.
LITERATURE REVIEW
- They developed a model to find the success of upcoming movies based on certain factors. The number of audience plays a vital role in a movie becoming successful
- The factorization Machines approach was used to predict movie success by predicting IMDb ratings for newly released movies by combining movie metadata with social media data
- Using the grossattribute as a training element for the model. The data are converted into .csv files after the pre-processing is done
- Using S-PLSA – the sentiment information from online reviews and tweets, we have used the ARSA model for predicting the sales performance of movies using sentiment information and past box office performance.
- A mathematical Model is used to predict the success and failure of upcoming movies depending on certain criteria. Their work makes use of historical data in order to successfully predict the ratings of movies to be released
- According to them, Twitter is a platform that can provide geographical as well as timely information, making it a perfect source for spatiotemporal models.
- The data they collected was gathered from Box Office Mojo and Wikipedia. Their data was comprised of movies released in 2016
- Initially having a dataset of 3183 movies, they removed movies whose budget could not be found or missed key features in the end a dataset of 755 movies were obtained. After Key feature extraction was completed.
- some useful data mining on the IMDb data, and uncovered information that cannot be seen by browsing the regular web frontend to the database.
- According to their conclusion, brand power, actors or directors isn’t strong enough to affect the box office.
- Their neural network was able to obtain an accuracy of 36.9% and compromising mistakes made within one category an accuracy of a whopping 75.2%
- They divided the movies into three classes rise, stay, and fall finding that support vector machine SMO can give up to 60% correct predictions
- The data was taken from the Internet Movie Database or IMDb as the data source, the data they obtained was from the years 1945 to 2017.
- A more accurate classifier is also well within the realm of possibility, and could even lead to an intelligent system capable of making suggestions for a movie in preproduction, such as a change to a particular director or actor, which would be likely to increase the rating of the resulting film.
- In this study, we proposed a movie investor assurance system (MIAS) to aid movie investment decisions at the early stage of movie production. MIAS learns from freely available historical data derived from various sources and tries to predict movie success based on profitability.
- The data they gathered from movie databases was cleaned, integrated, and transformed before the data mining techniques were applied.
- They used feature, extraction techniques, and polarity scores to create a list of successful or unsuccessful movies. This was done by gathering the data using IMDb and YouTube.
PROBLEM STATEMENT
in this Movie Success Rate Prediction project, The method of using the ratings of the films by the cast and crew has been an innovative and original way to solve the dilemma of film producers. Film producers have often trouble casting successful actors and directors and still trying to keep a budget. Looking at the average ratings of each actor and director together with all the films they participated in should be able to give the producer a good idea of who to cast and who not to cast in a film that is to be out right now.
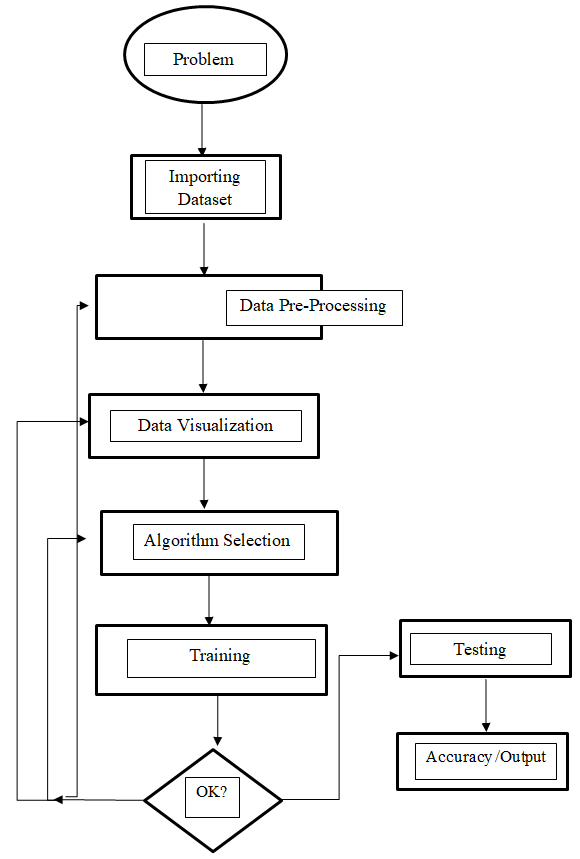
Implementation:
- Data Preprocessing & Correlation Analysis
- Application of Decision Tree Algorithm
- Application of Random Forest Algorithm
RESULTS & CONCLUSION
After testing both the algorithms on the IMDb dataset i.e. Decision Tree and Random Forest algorithm, we found that the Random Forest algorithm got a better accuracy (99.6%) on the data rather than the decision tree algorithm in which we obtained just 60% accuracy.