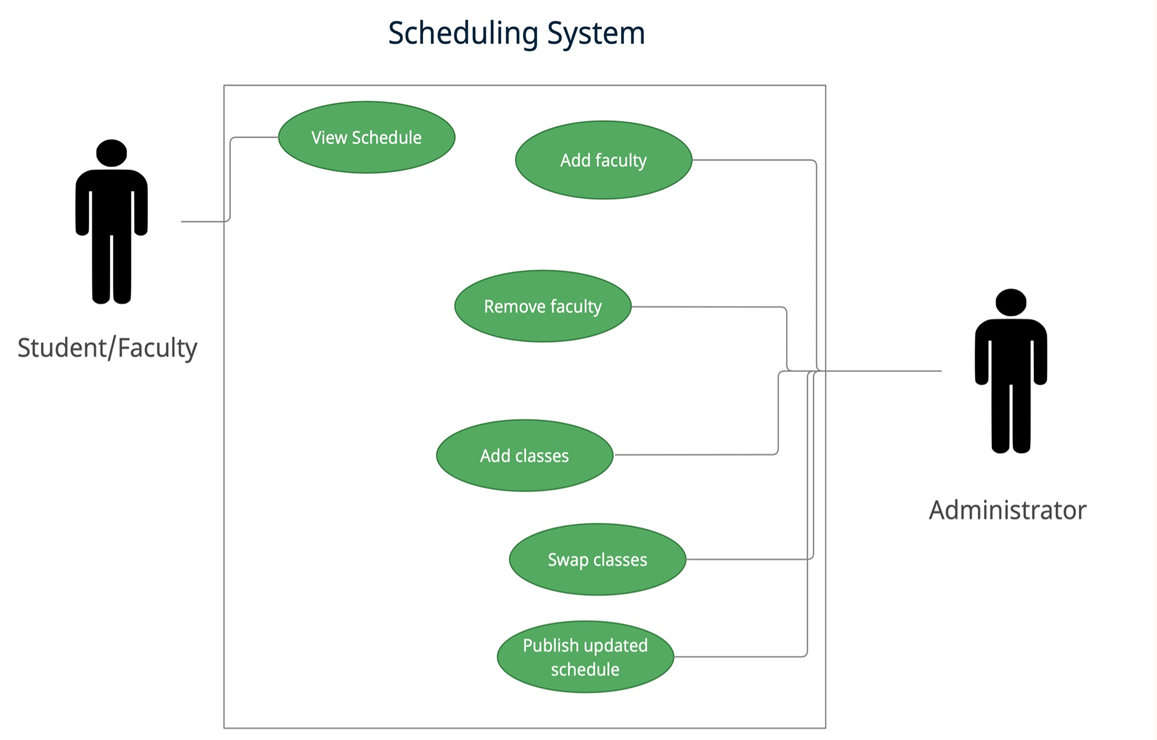
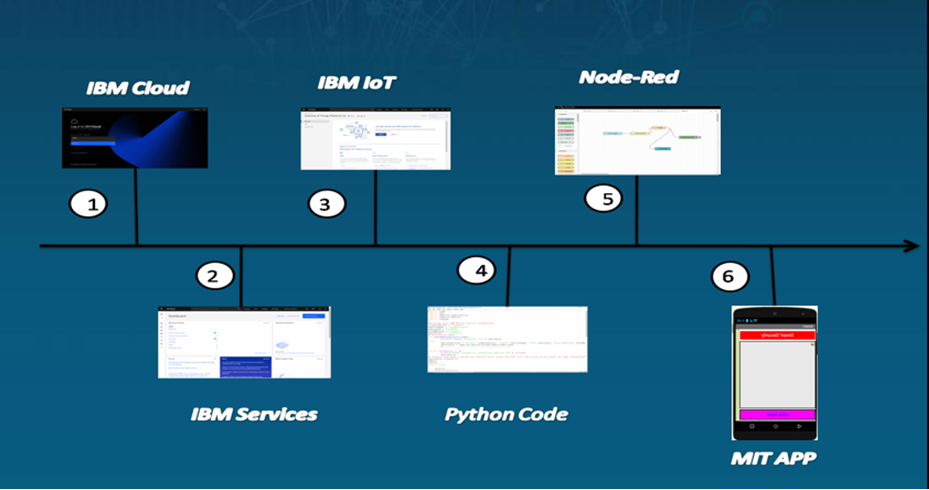
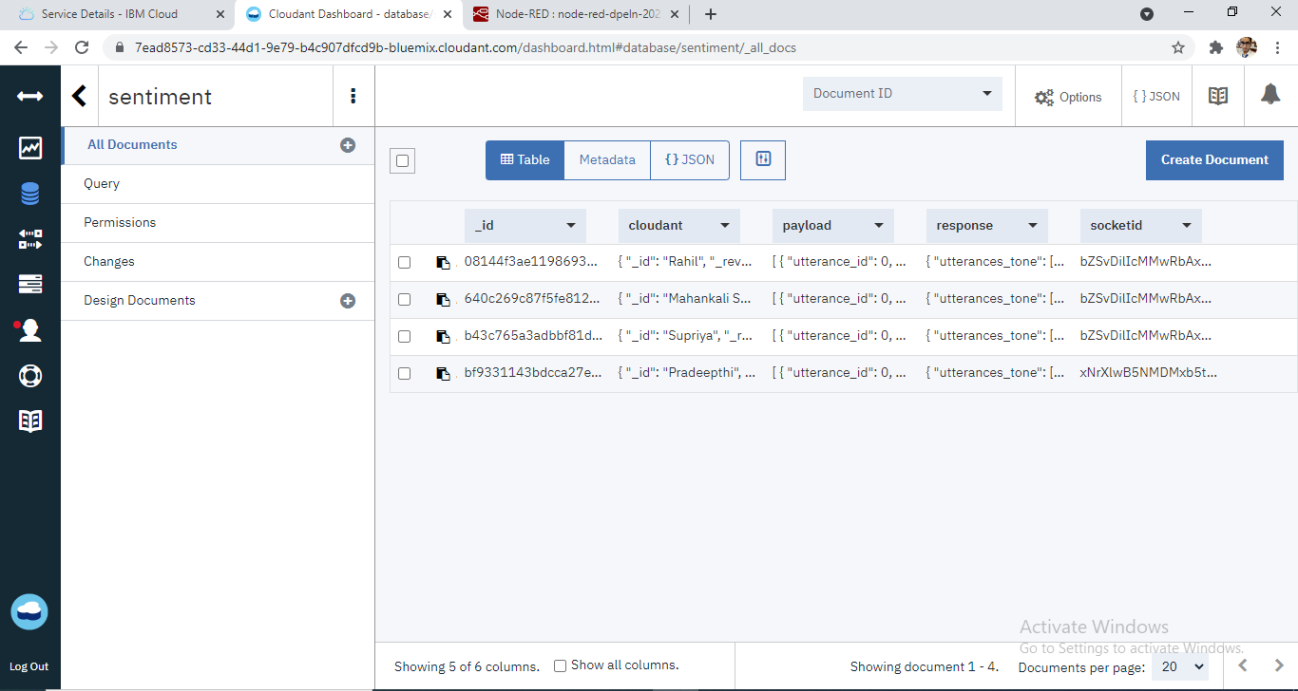
Purpose of the Project
To avoid several health issues, we should monitor our body fitness by using various fitness prediction gadgets like smartwatches, oximeters, B-P machines, etc. we can monitor our B-P, calories burnt, bone weight, etc. the devices work with smart device technology to exchange data via Bluetooth communication protocol. Here, in this project, we import the data which consists of (date, step count, mood, calories burned, hours of sleep, bool of activity, and weight in kg) and split the dataset into the testing set and training set. We are using a random forest classifier in this project.
Existing problem
Body fitness prediction play’s a key role in leading a healthy life. Fitness is a state of health and well-being, more specifically the ability to perform daily activities body fitness is generally achieved through proper nutrition and physical exercise, and rest. By this, we are losing our body fitness and it leads to various chronic issues
Proposed solution
Importing Dataset
Exploratory Data Analysis ]: df. shape
Here, in this project, we import the data which consists of (date, step count, mood, calories burned, hours of sleep, bool of activity, and weight in kg) and split the dataset into the testing set and training set. We are using a random forest classifier in this project.
EXPERIMENTAL INVESTIGATIONS
Dataset:
We will use the body fitness prediction dataset which was retrieved from Kaggle.com.
- Check if there are associations between physical activity (by counting steps), caloric expenditure, body weight hours of sleep, and the feeling of feeling active and/or inactive.
- Compare caloric expenditure between the categories of mood and self-perceived activity (active and inactive)
- Compare the hours of sleep between the categories of mood and self-perceived activity (active and inactive)
- Compare body weight between categories of self-perceived activity (active and inactive)
- Database The database has 96 observations, and 7 columns. Its quantitative variables are “number of steps” (step_count), “caloric expenditure” (calories_burned), “hours of sleep” (hours_of_sleep and “body weight” (weight_kg). And qualitative variables “dates” (date), “mood” “(mood), self-perceived activity” active or inactive “(bool_of_active). The variable” humor “was assigned the value” 300 “to mean” Happy “, the value” 200 “for” Neutral “and” 100 “for” sad “and for the variable” self-perceived activity
- Contingency tables of categorical variables will be exposed.
- A correlation matrix between variables will be presented
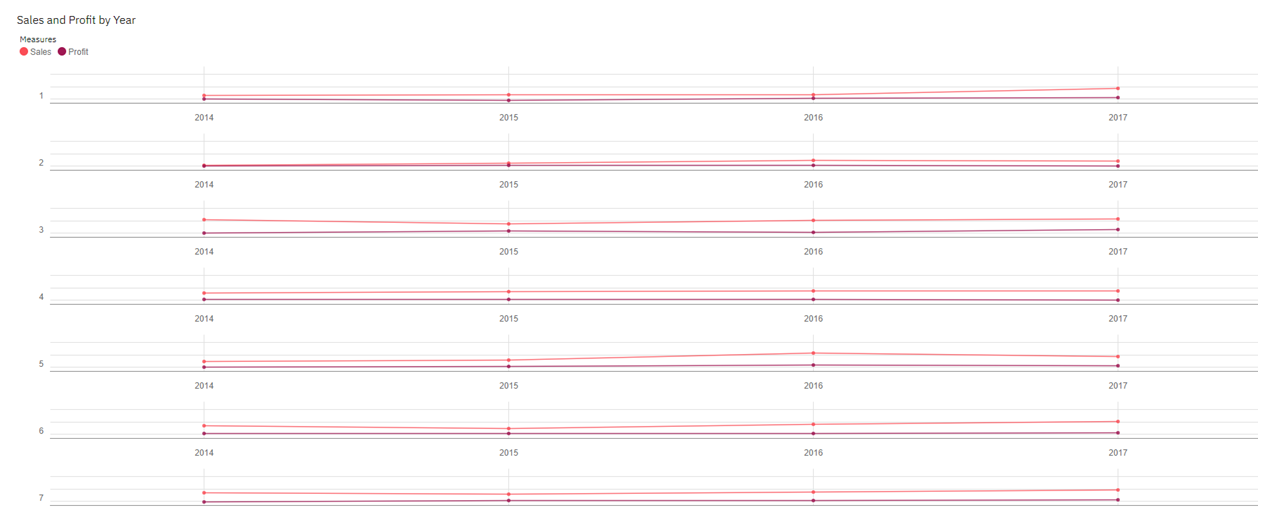
- Bar charts and violins to demonstrate the distribution of quantitative variables by categories
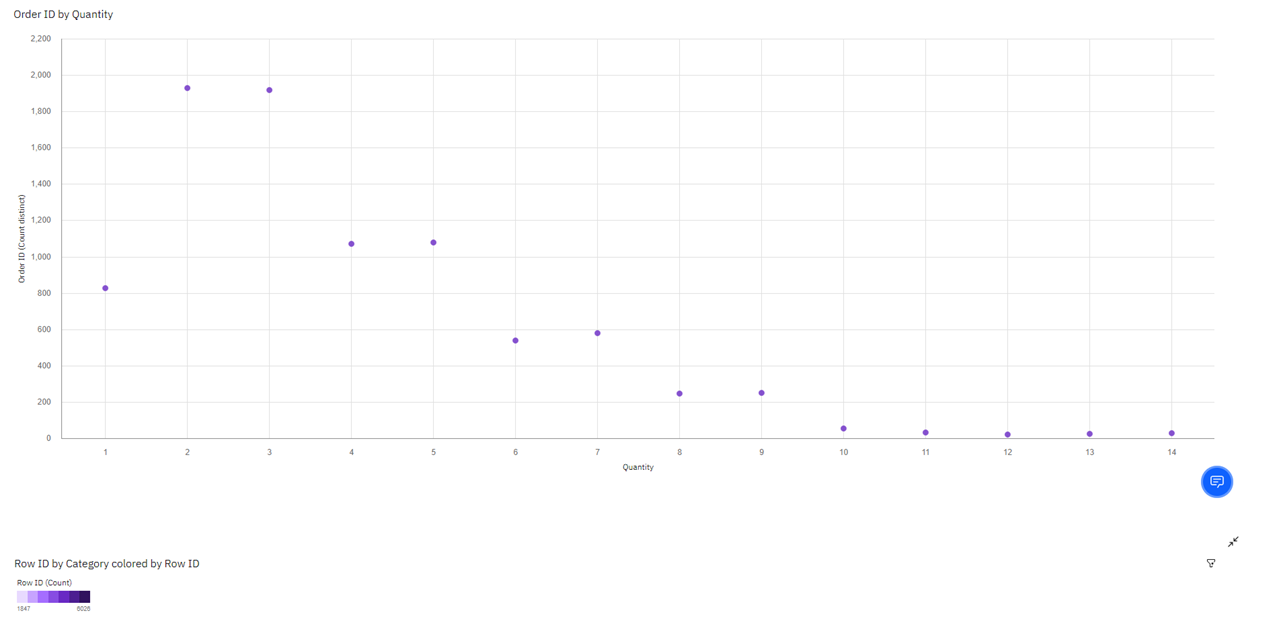
- Scatter plot for analysis of the possible linear relationship between two variables
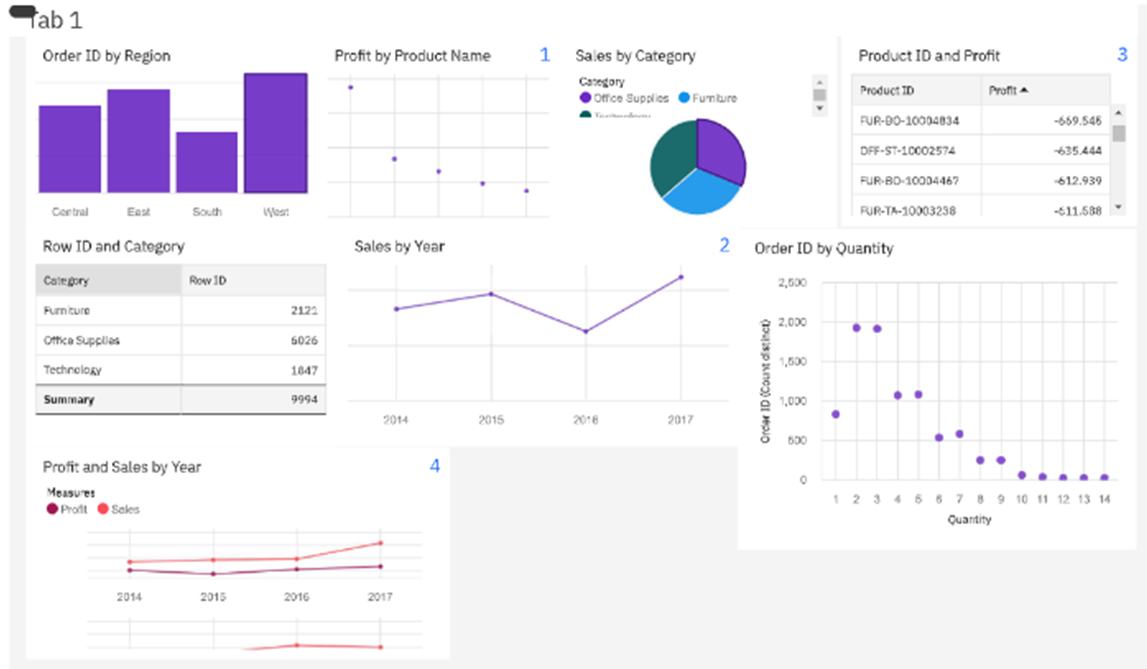
RESULT
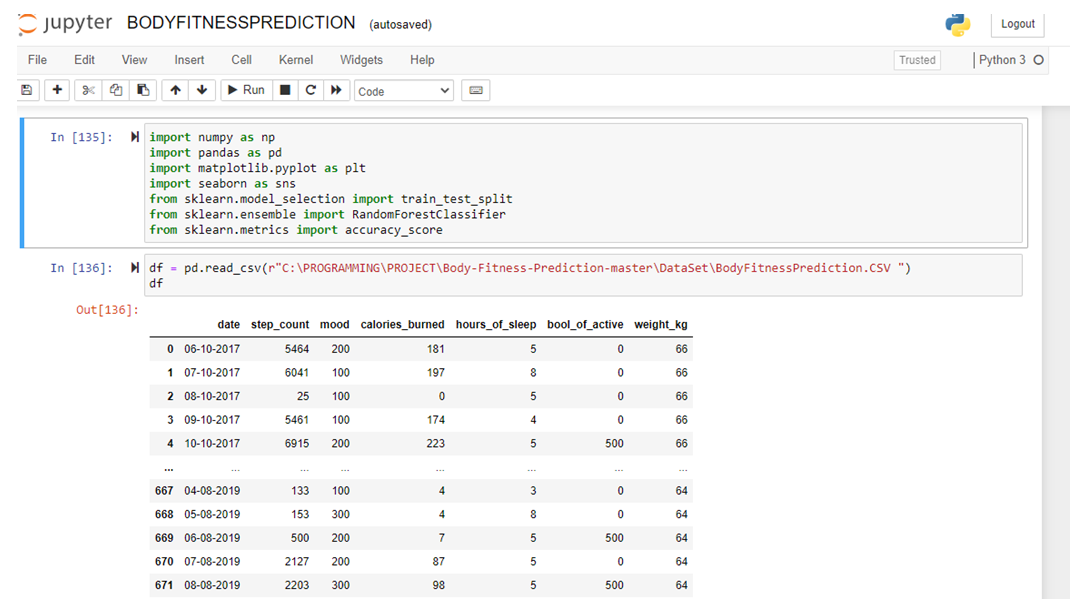
RANDOM FOREST CLASSIFIER
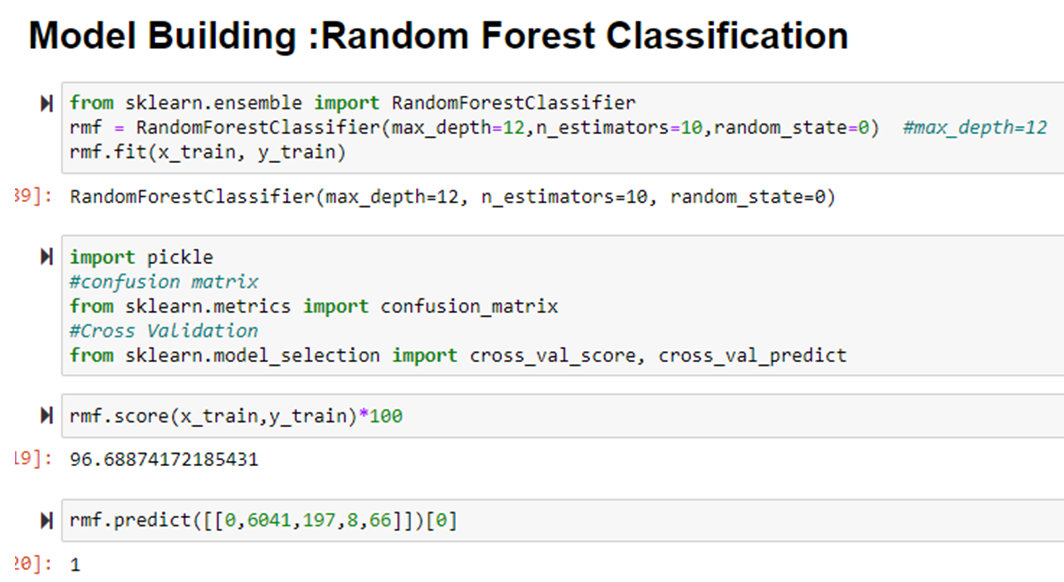
CORRELATION PLOT
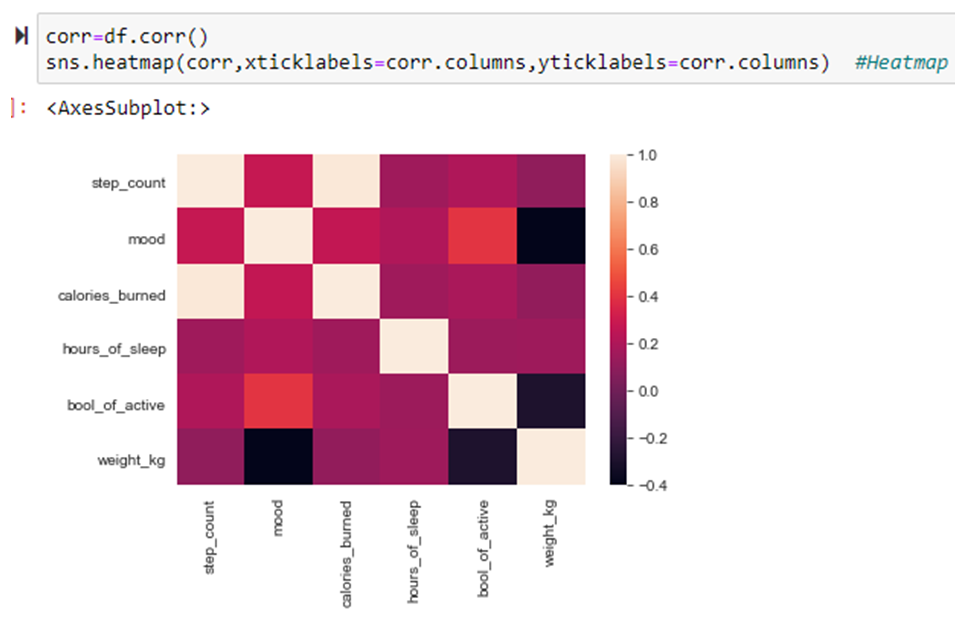
FINAL RESULT:
APPLICATIONS
There are so many different kinds of applications used to predict the fitness of Human beings today.
TRAINING AND TESTING:
Splitting the data:
We use sklearn. ensemble module train_test_split which is used for the training and testing part.
Dependent and Independent variables:
Independent variables contain a list of variables on which the bool of activity is dependent.
The dependent variable is the variable that is dependent on the other variable’s values.
Independent variables are mood,step_count, calories burned, hours of sleep,weightkg.
The dependent variables are bool_of_active.
MODEL BUILDING:
We use Random Forest Classifier for predicting Body Fitness Prediction. Because it gives an accurate prediction.
CONCLUSION
We have analyzed the Body fitness prediction Data and used Machine Learning to Predict the fitness of a human being. We have used a Random Forest classifier and its variations, to make predictions and compared their performance. xgboost regressor has the lowest RMSE and is a good choice for this problem.