
Project description
In India, delays in diagnosing diseases are a major problem due to a lack of medical professionals. The typical scenario, which is mainly in rural and slightly urban areas:
1. A patient who sees a doctor with certain symptoms.
2. The doctor will perform some tests, such as blood and urine tests, depending on the symptoms.
3. The patient undergoes the above tests in the analytical laboratory.
4. The patient takes the reports back to the hospital, where they are examined and diagnosed.
The goal of this project is to reduce some of the delays caused by unnecessary detours between the hospital and the pathology laboratory. Historically, work has been done to detect the onset of heart disease, such as Parkinson’s, and machine learning algorithms have been developed to predict liver disease in patients based on a variety of characteristics.
Problem statement
The problem report is officially defined as follows:
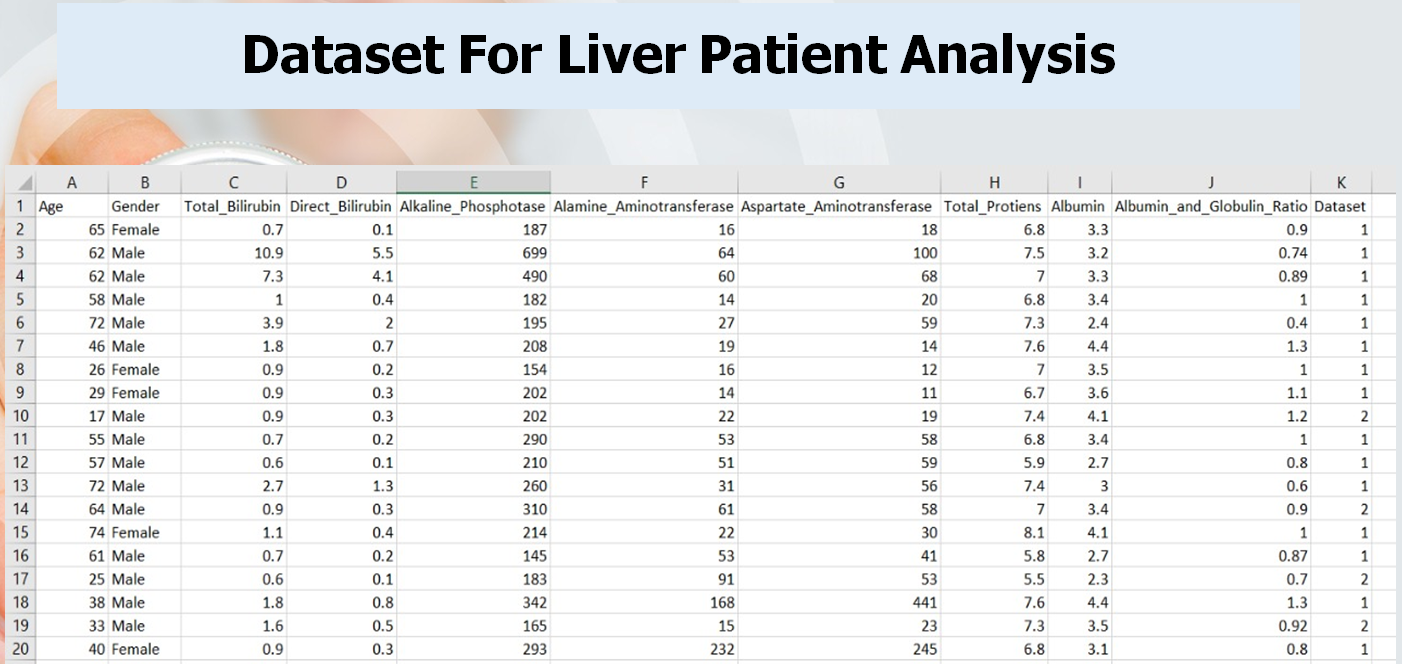
“Considering the data set containing the various attributes of 584 Indian patients, use the functions in the data set and determine a controlled classification algorithm to determine whether a person is suffering from liver disease. This data set contains 416 liver recordings and 167 non-liver recordings. collected in northeastern Andhra Pradesh. This data set contains records of 441 male patients and 142 female patients. Each patient over the age of 89 is “90” years old.
Strategy
This seems to be a classic example of controlled learning. We are given a fixed number of functions for each data point, and our goal is to teach different controlled learning algorithms based on this data, so that when a new data point appears, our best-performing classifier can be used. information point as a positive or negative example. Detailed information on the number and types of algorithms used for training is contained in the “Algorithms and Techniques” section of the “Analysis” section.
Conclusion
Initially, the data set was studied and prepared for inclusion in the classifiers. This was achieved by removing some rows containing zero values, modifying some columns indicating the skewness, and using appropriate conversion techniques (a hot coding) to make the labels more useful for classification purposes. The performance indicators for which the models will be evaluated have been resolved. The data set was then divided into a reading and testing package.
First, a simple predictive and base model (“Logistic Regression”) was developed in the data set to determine the value of the base accuracy. The biggest challenge in implementing this project was in two areas: defining learning algorithms and selecting the appropriate parameters for precise configuration. Initially, making a decision on 3 or 4 methods out of the many choices available at sklearn was very tedious.
Algorithms and Techniques used to develop this Liver Patient Analysis Machine Learning Project are
1. Random Forest Classifier:
2. Gaussian Naive Bayes Classifier
3. Logistic Regression:
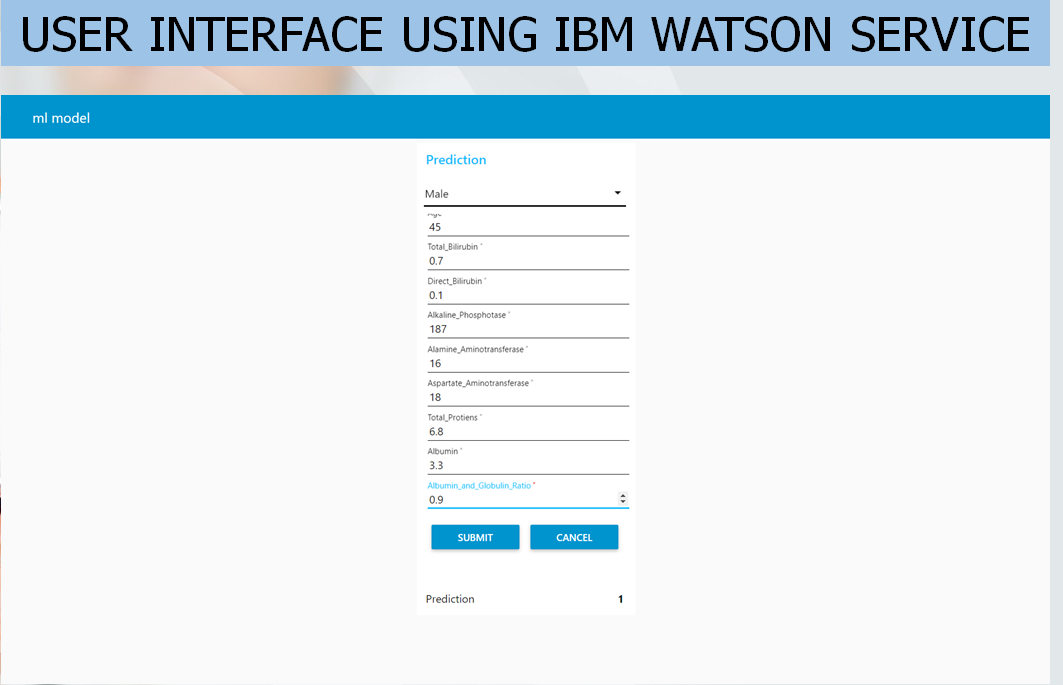
Download the complete Liver Patient Analysis Machine Learning Project Python source code, project report, PPT Presentation.
For more details about the project visit this page