
Retail banking
Typical mass-market banking is used by local clients of local branches of large commercial banks. The services offered include checking and savings accounts, mortgages, personal loans, debit/credit cards. Attention is paid to the customer.
The main problems in this sector are:
Which product is right to recommend to the customer?
What is the best time to sell a product?
What is the most effective channel to communicate with the customer?
PROBLEM STATEMENT
The data in this regard are related to the direct marketing campaigns of the banking institution. Marketing campaigns are based on phone calls. Often multiple contacts with a customer were required to reach the product (term bank deposit) whether to subscribe (‘yes’) or unsubscribe (‘no’). The goal is to know in advance whether the customer will sign up for a term deposit.
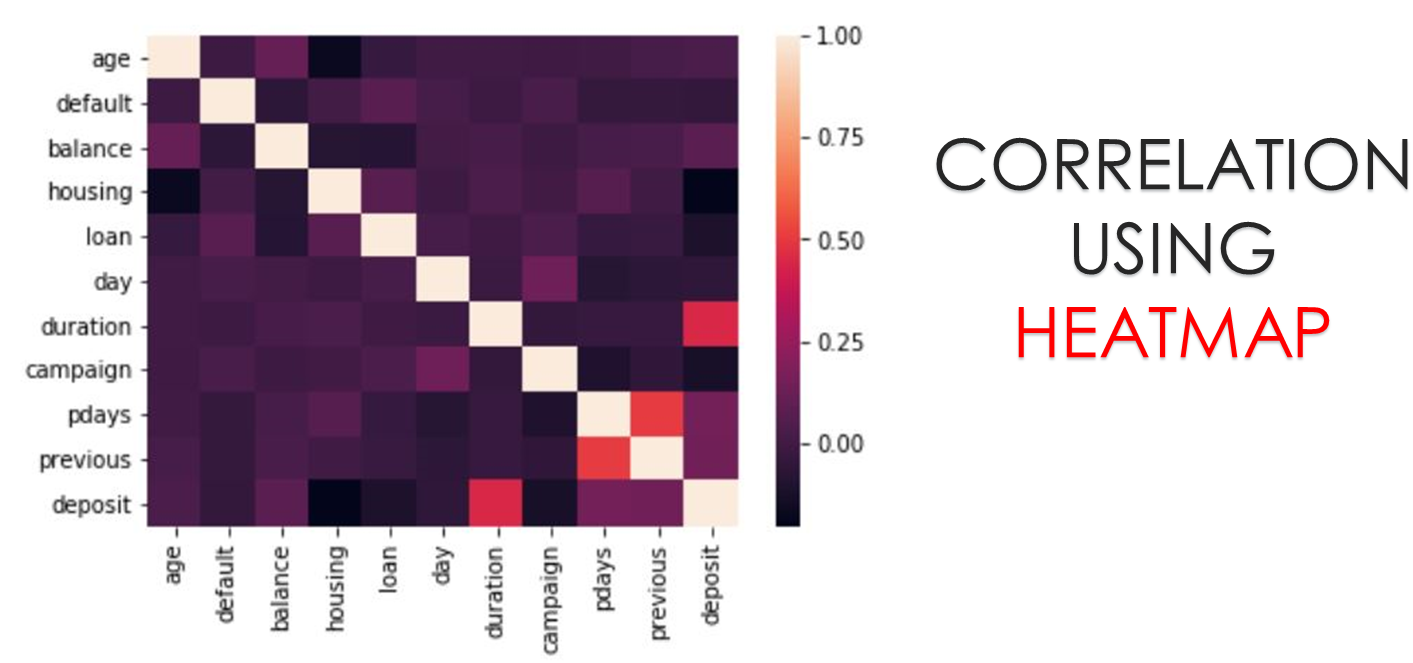
ABOUT THE INFORMATION
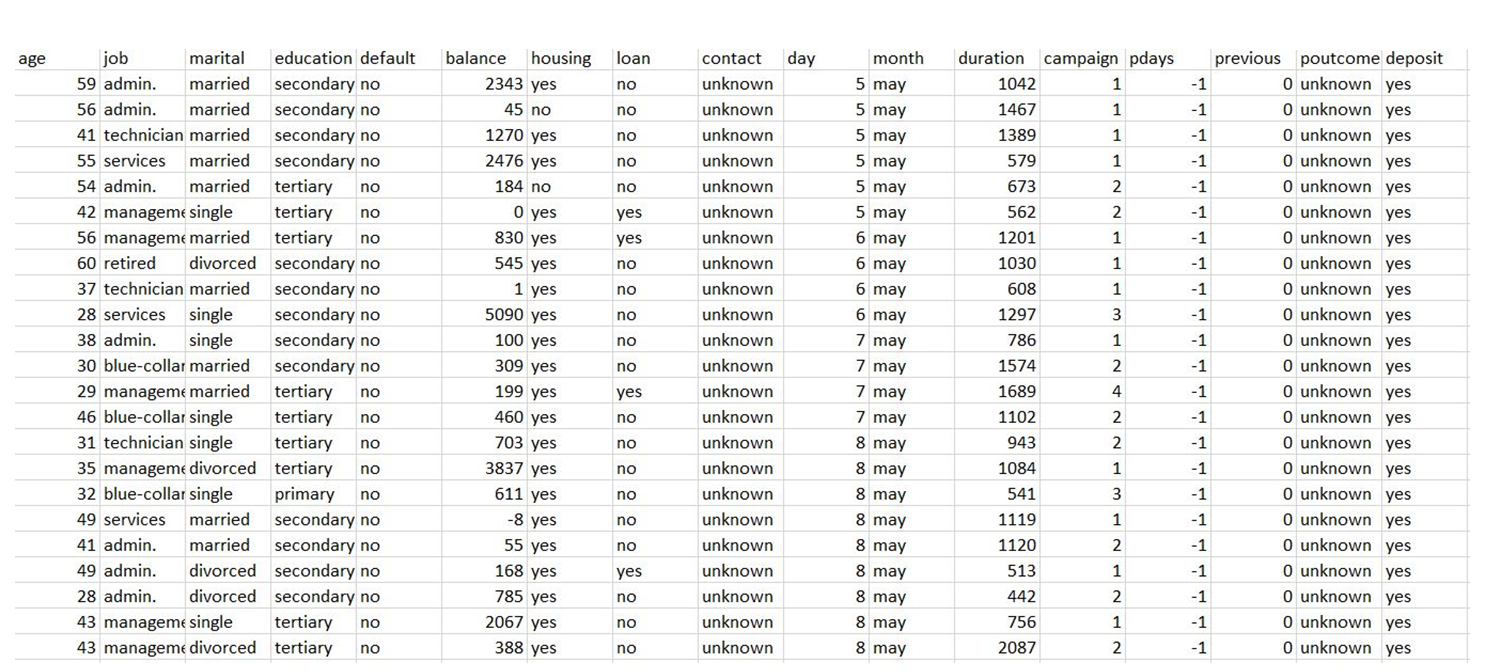
This is a classic marketing bank data package uploaded to the UCI machine learning repository. The data set provides you with information about the financial institution’s marketing campaign, which you need to analyze to find ways to look for future strategies to improve the bank’s future marketing campaigns.
These are the columns in the data set:
Age: age of the client (quantitative)
Job: Client’s profession – (categorical) (administrator, worker, entrepreneur, housekeeper, manager, retiree, self-employed, service provider, student, technician, unemployed, unknown)
Marital: Client’s marital status – (categorical) (divorced, married, single, unknown, note: divorced means divorced or widowed)
Education: Client’s level of knowledge – (categorical)
By default: Indicates whether the customer has a debt – (categorical) (no, yes)
Balance: average annual balance, in euros (quantitative).
Housing: Does the client have a home loan? – (categorical) (no, yes)
Loan: Is the client a personal loan? – (categorical) (no, yes)
Contact: Contact type – (categorical) (unknown, mobile, phone)
Date: The date of the last contact with the customer.
Month: Last customer contact month – (categorical) (January-December)
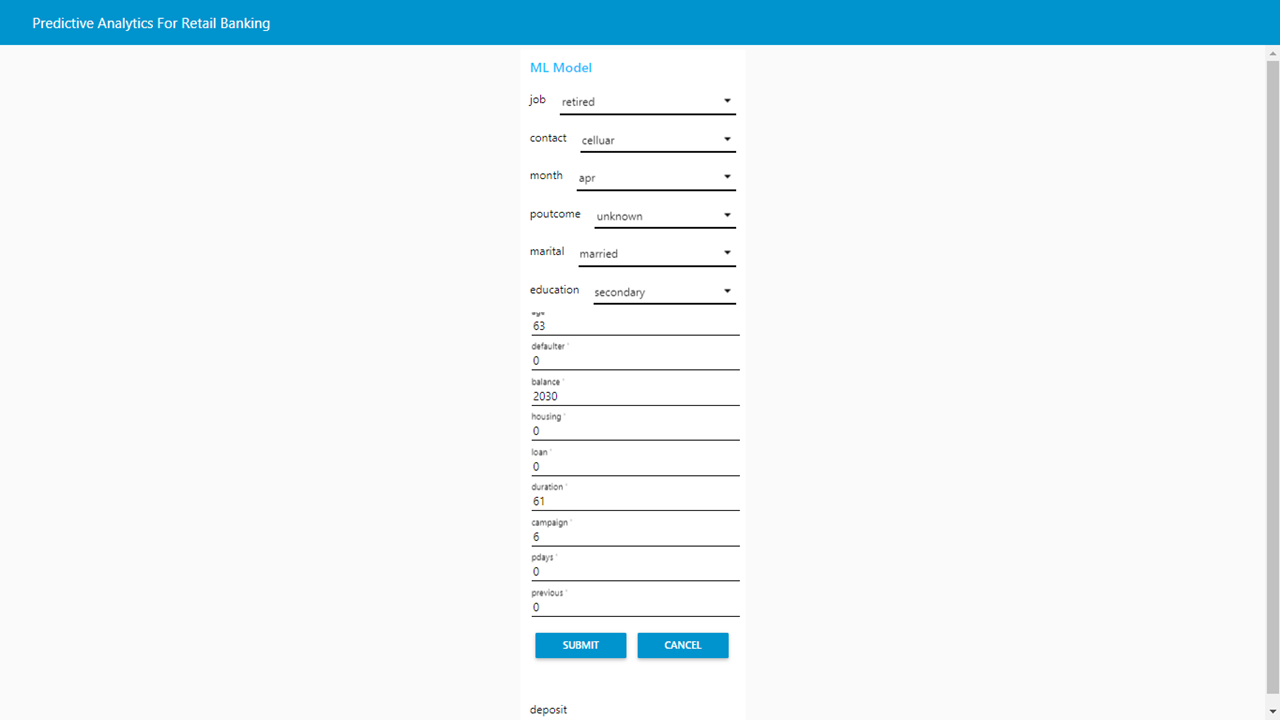
CONCLUSION
In the real world, most classification problems are two-sided. Also, data sets have almost no meaning. In this post, we cover strategies to combat unbalanced data sets with missing values. We will also explore different ways to build packages within the sklearn. Here are some exceptions:
Accuracies compared
- K-nearest Neighbour: 75.3%
- Logistic Regression: 80.9%
- Decision Tree: 78.2%
- Random Forest Classifier: 78%
- Support vector Machine: 53%
Sometimes we may be willing to give up some model improvements if this estimate is much more complex than the percentage change in metric improvement.
When building ensemble models, try to use as many different good models as possible to minimize the correlation between basic students. We could improve the model of our concentrated ensemble by adding a dense neural network and other types of basic learners, as well as adding more layers to the concentrated model.
Easy Ensemble generally works better than other re-modeling methods.
Download the complete Predictive Analytics for Retail Banking Machine Learning Python Project Source Code, Report, PPT.
For more details about the project visit this page