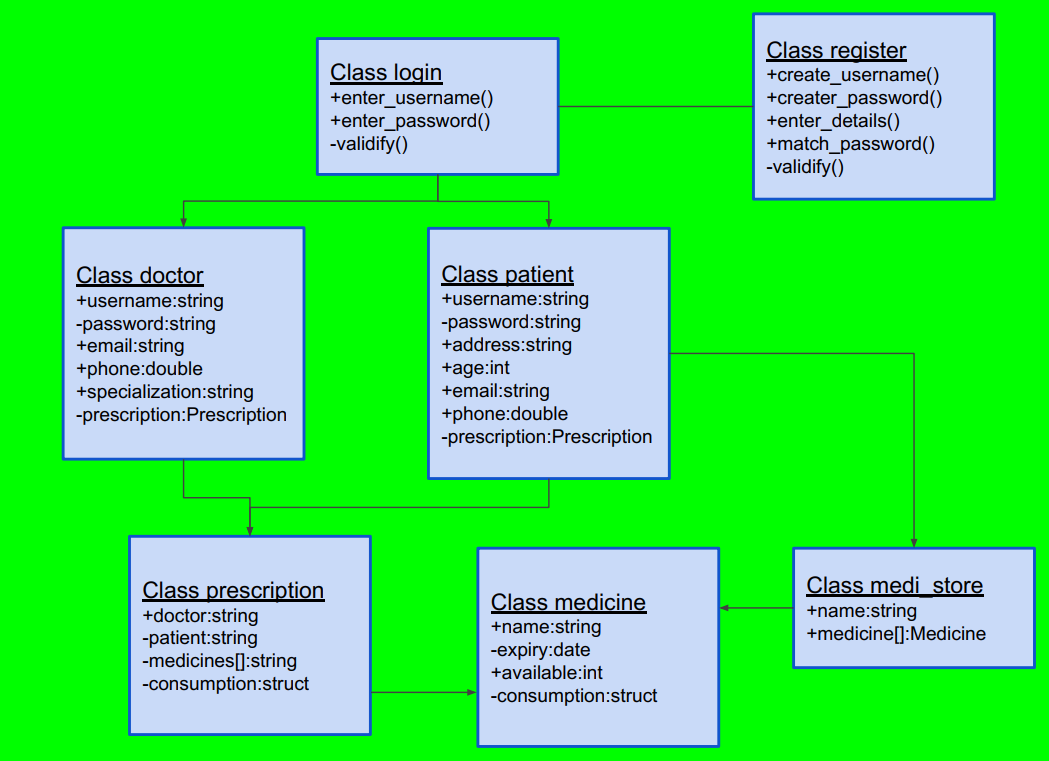
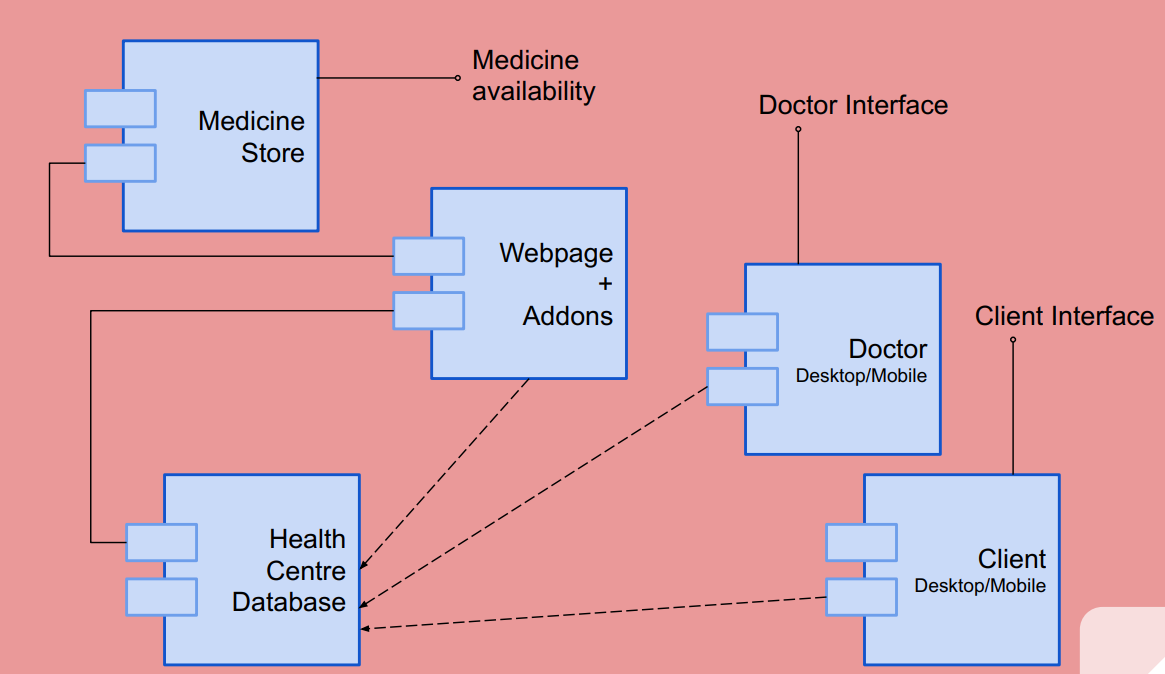
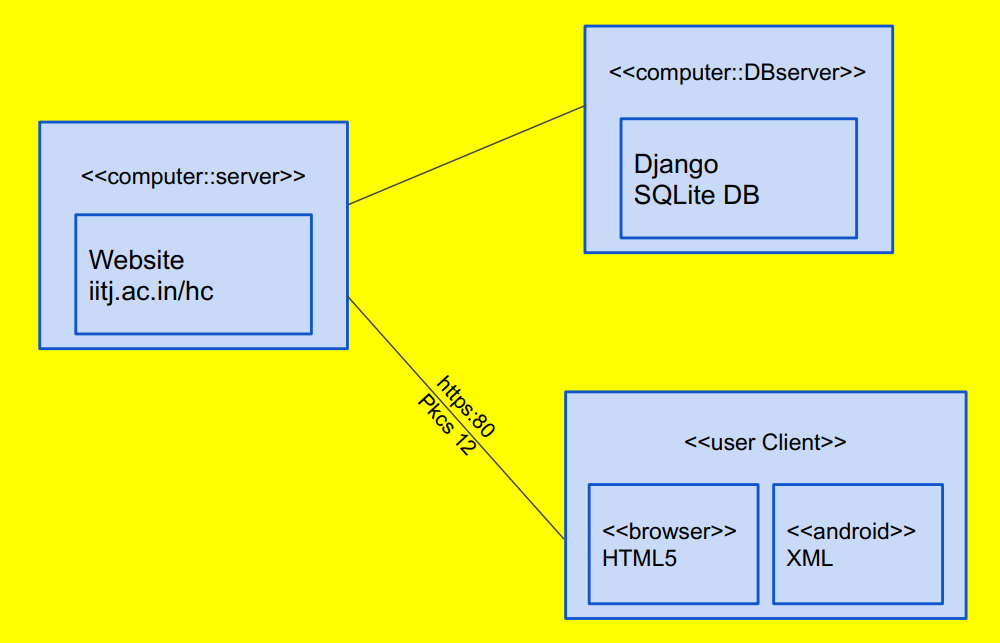
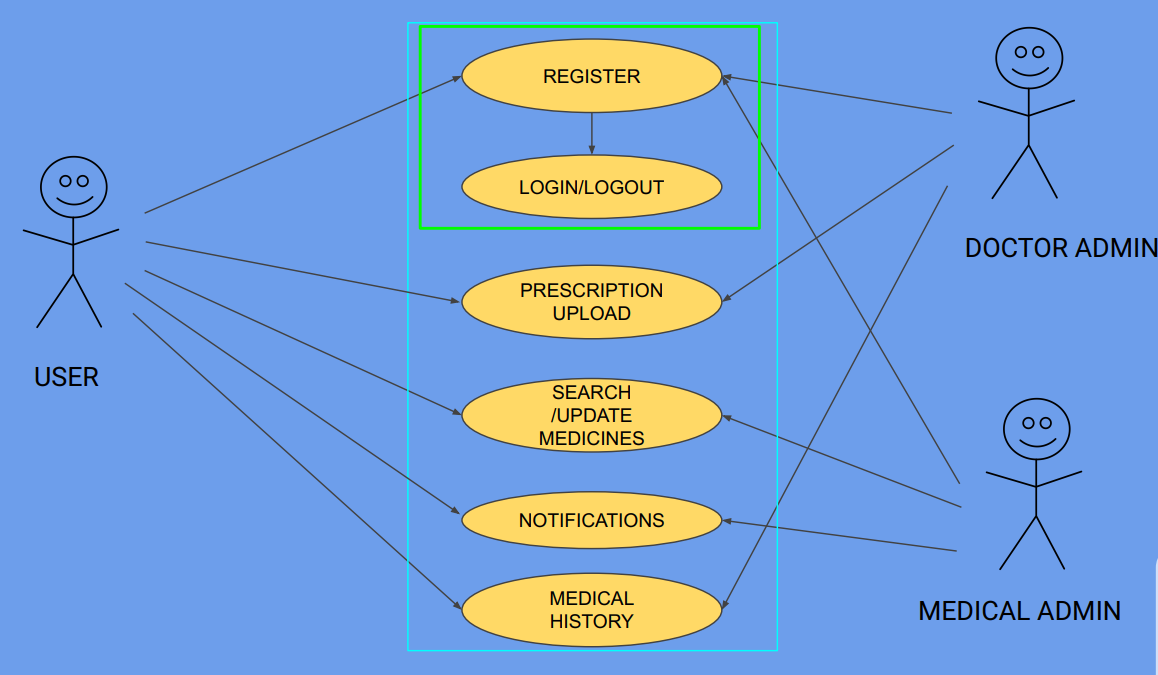
OBJECTIVE:-
We have seen blind people facing many problems like fake Currency Notes Detection in our society. So, we have come up with some solutions for some problems they face. As they are blind, they are not able to read the medicine’s name and they always depend on another person for help. Some people take advantage of their disability and cheat them by taking extra money or by giving them less money. And by this Currency Notes Detection project, we are making them independent in terms of medical benefits.
METHODOLOGY: –
To overcome the problem of blind people we have come up with an innovative idea, where we are making use of machine learning, image processing, OpenCV, text-to-speech, and OCR technologies. To make their life comfortable.
In this Currency Notes Detection project, we are using a camera for getting the input, where the inputs are pictures of medicine and currency. These images can be manipulated using image processing and OpenCV. Once the processed image is obtained then it is cropped and thresholding is done, In the next stage we will extract the name of the medicine, then we will convert that text into speech using text-to-speech technology.
Similarly, we will also take pictures of currency, and then by using image processing and machine learning we will compare the picture with a predefined database of the currency that we have already prepared. The next process will be to convert the value of currency into text and then the text is converted into speech using text-to-speech technology.
Block Diagram: –
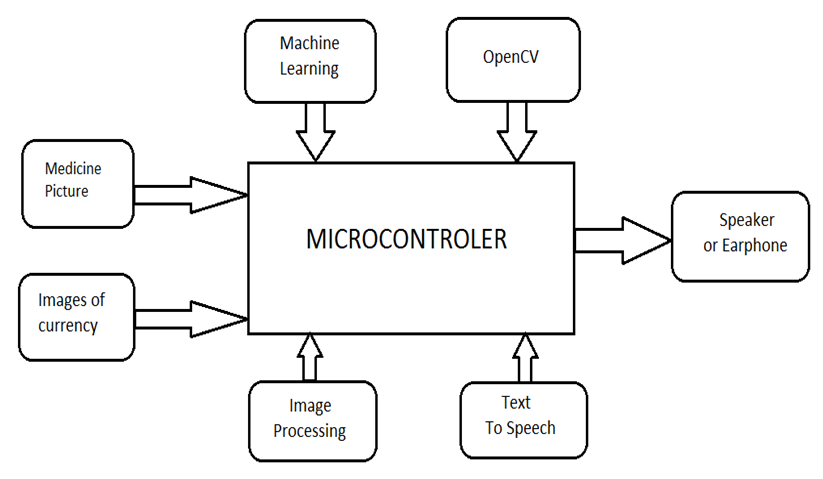
Technology Used:
- Image Processing: To extract necessary information
- OpenCV: To threshold image, color shifting, scanning, and cropping, setting grey level, and extract contours
- Python 3: To set up the environment and interact with devices
- OCR (Optical Character Recognition)
- Machine Learning: Handwritten data is trained in a classifier to process manual marks awarded.
Results
The Detection of Currency Notes and Medicine Names for the Blind People Project can help the blind person in the detection of currency notes and medicine names. By this, the blind person would take care of himself without the help of any caretakers. This would make their life easier and simpler. The talk-back feature used would help them to access the application easily without any complications.
- This project would help blind people to detect the proper currency that they have received or which they need to give without being cheated for receiving the wrong currency or by avoiding giving the wrong currency. This would make them economically stable and strong
- Not only in currency detection but also this project would help blind people to recognize the name of the tablet and also help them to know how many dosages they need to take as per the name of the tablet.
This Currency Notes Detection project would help blind persons both in an economical way and in the perspective of health. This would make their life easier and make them confident.
Applications
- Blind persons will be able to recognize the correct currency without getting cheated in any type of money transaction.
- Blind persons always need not be dependent on others to know which medicines they need to take at a particular time.
Advantages
- This project will work on mobile phones only no need to buy any extra things.
- This work is implemented using TalkBack for android and Voiceover for iOS which means blind people can easily access the application.
- Easy to set up.
- Open-source tools were used for this project.
- Accessible to all devices irrespective of the OS.
- Cheap and cost-efficient.
Disadvantages
- It is very difficult to determine whether the currency is a fake one when it is an exact copy of the real currency.
- For the medicine part, the image should be taken from any side where the name of the medicine is written.
Conclusion
This work shows how visually impaired people (blind persons) can protect themselves from getting cheated in terms of money transactions and also how to reduce the dependency on other people to take the right amount of medicine at the right time Whenever the blind person takes the image using his phone camera the image will be compared with the data set which is created.
After comparing the image if it gets the accuracy above the threshold value then it will give the spoken feedback to the person by saying the value of the currency Similarly in the case of medicine detection extract the name of the medicine and gives the spoken feedback as how many times that person needs to take the medicine, thus making this work as one of the assistants for a blind person.
Future Scope
• Include the data set of photos that contain a person’s images it can also be used to detect a person who has a blind person meets.
• It can also be used to track the blind person using GPS