Modify is a song suggested that recommends the song to the user according to his mood. ‘Modify’ will do the job leaving the user to get carried away with the music.
I/We, student(s) of B.Tech, hereby declare that the project entitled “MOODIFY (Suggestion of Songs on the basis of Facial Emotion Recognition)” which is submitted to the Department of CSE in partial fulfillment of the requirement for the award of the degree of Bachelor of Technology in CSE. The Role of Team Mates involved in the project is listed below:
- Training the model for facial emotion recognition.
- Designing the algorithm for image segregation.
- Algorithm designing for music player.
- Graphical user interface designing.
- Testing the model.
- Collection of data for model and music player.
- Preprocessing of the data and images.
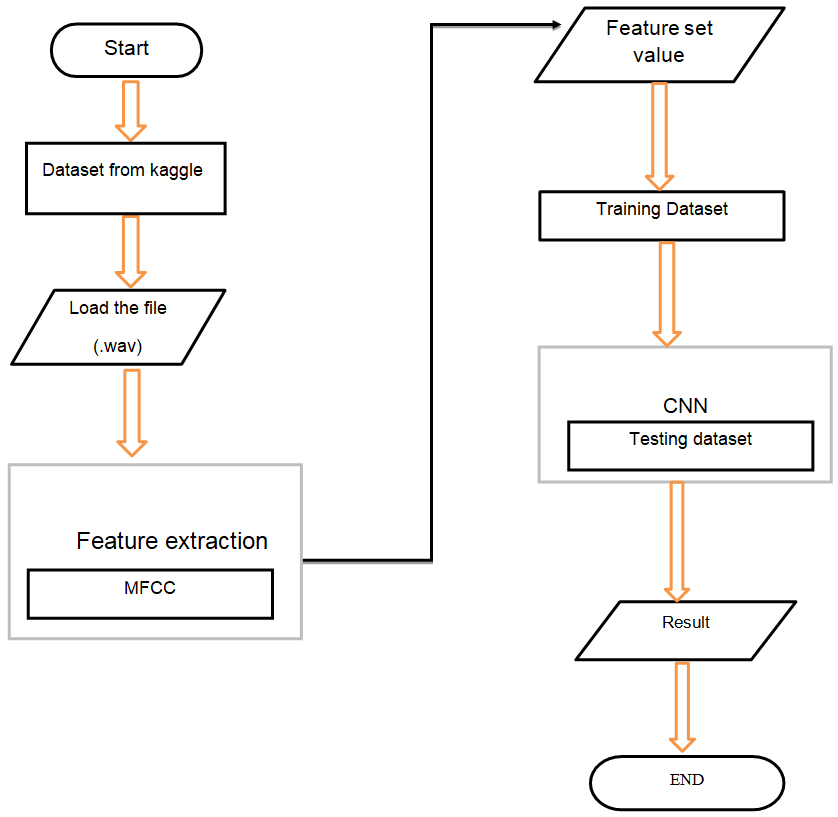
Dataset:
The dataset we have used is “Cohn-Kanade”.
This dataset is classified so we cannot provide the actual dataset but the link for you to download is :
http://www.consortium.ri.cmu.edu/ckagree/index.cgi
And to read more about the dataset you can refer to:
http://www.pitt.edu/~emotion/ck-spread.htm
Feature Extraction and Selection:
1. Lips
2. Eyes
3. Forehead
4. Nose
These features are processed by CNN layers and then selected by the algorithm and then they are converted to a NumPy array then the model is trained by that and the following three classifications are made.
How this project works:
- First Open the Application, CHOOSE THE MODE IN WHICH YOU WANT TO LISTEN to THE SONG
- Then it shows “YOUR MOOD, YOUR MUSIC”
- Press “OKAY TO CAPTURE THE IMAGE”
- After that press “c” to capture
- You seem Happy please select your favorite genre
- You seem Excited please select your favorite genre
- You Seem Sad please select your favorite genre
CODE DESCRIPTION
- All libraries are imported into this.
- Model Initialization and building.
- Training of test and testing.
- Training our model
- Model Building, Splitting of test and train set, and training of the model.
- Saving a model.
- Loading a saved model.
- Saving image with OpenCV after cropping and loading it and then the prediction
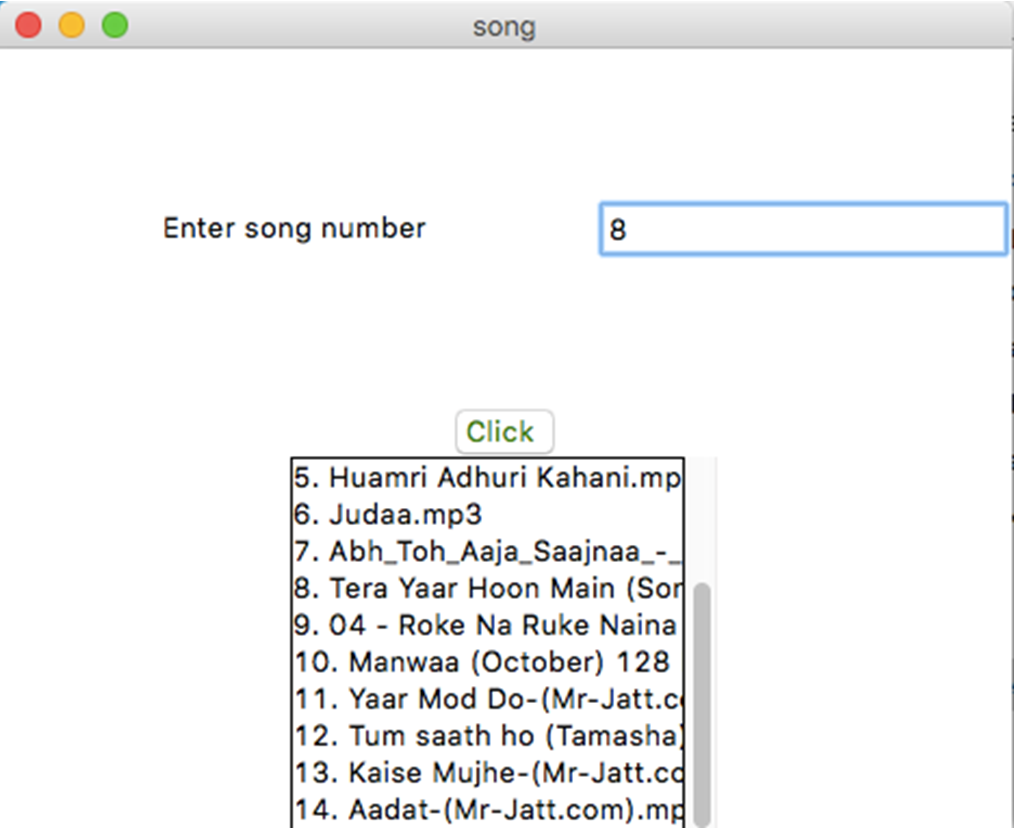
- Suggesting songs in Offline mode
- Suggesting songs online(Youtube)
- Rest of the GUI part
- Variable Explorer
IPython Console
- Importing Libraries
- Model Training
- Model Summary
- Online Mode
- Offline Mode
GUI
- Splash Screen
- Main Screen
- Selection screen
- Display songs and then select them, after that they will play
Summary
We successfully build a model for Facial Emotion Recognition(FER) and trained it with an average accuracy over various test sets of over 75%. Then we successfully build a Desktop application to suggest songs on the basis of their facial expression and hence completed our project. This FER model can be widely used for various purposes such as home automation, social media, E-commerce, etc and we have the motivation to take this project to a next level.
Download the complete Project code, report on MOODIFY – Suggestion of Songs on the basis of Facial Emotion Recognition Project