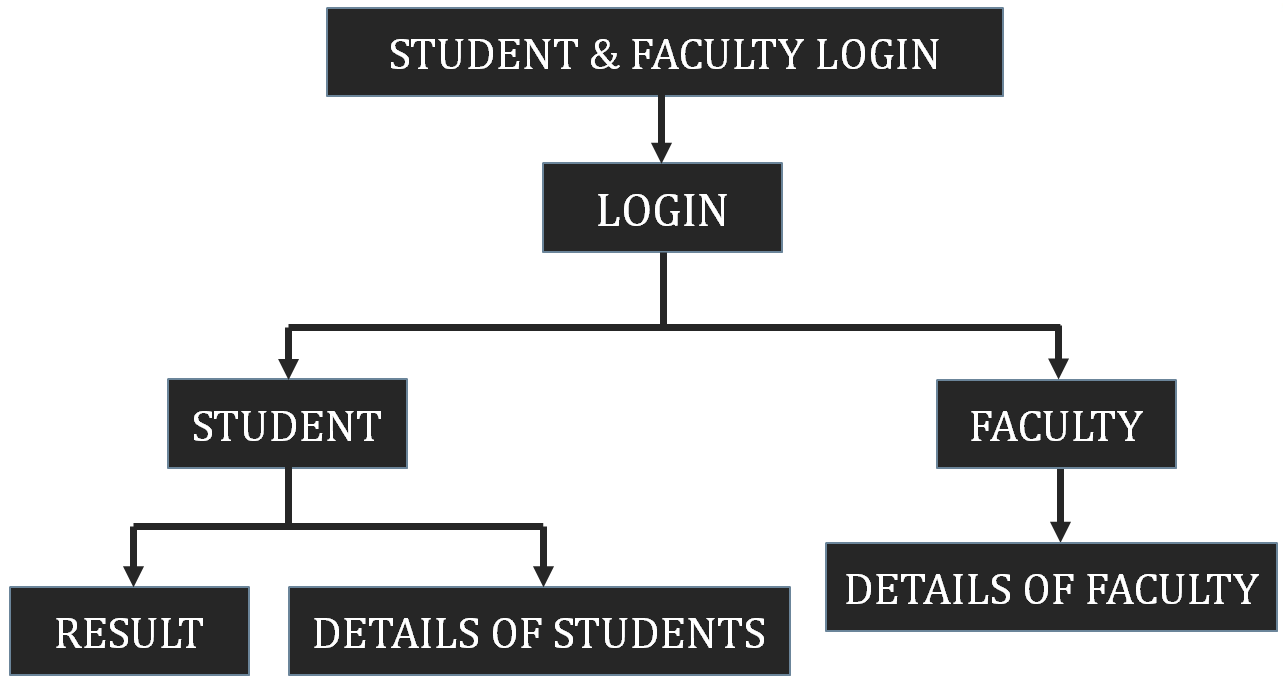
This Project simulates the working of an online shopping portal where customers can buy products. Our Online Shopping Management System project is a purely console-based application and is implemented using the programming language JAVA.
This Java Console Application contains mainly two panels :
- Admin Panel – functions provided like managing products and customers
- Customer Panel – functions provided like buying products and making payments
A total of 8 class files have been created which are :
- Database connection.java
- Shop.java ( This is the main or the starting point of the project )
- Admin.java
- Customer.java
- Products.java
- Cart.java
- Payment.java
- Bills.java
Java Concepts used in the project are :
- String manipulations
- Collections framework in form of ArrayList
- JDBC
- Exception Handling
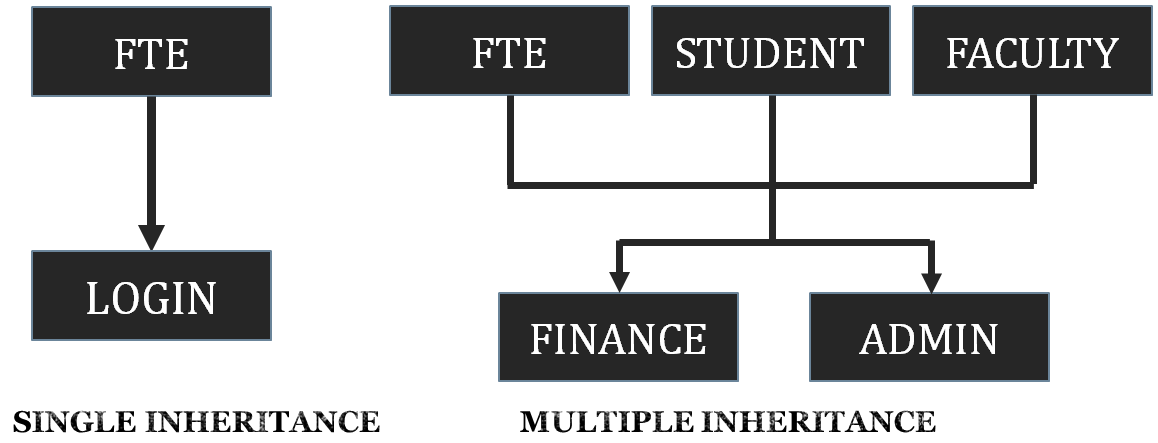
- Inheritance
- Classes and Objects
- BufferedReader for taking entry
ROLE OF EACH MEMBER IN THE PROJECT
- Designed class files – DatabaseConnection.java, Shop.java, Admin.java, and Customer.java and contributed to Debugging
- Designed class file – products.java and contributed to Debugging
- Designed class file – bills.java and contributed to Debugging
- Designed class files – Payment.java and Cart.java and contributed to Debugging
- Combination of class files in the end and for their joint working, Each member contributed equally.
DETAILS OF CLASS FILES
MAIN CLASS ( superclass ) = Shop.java
SUBCLASSES of Shop.java = admin.java and customer.java
Shop.java :
Main functions = registration of customer or admin, login into system Entry through buffered Reader
Array List used in login function to store id, password, and user type ( C for the customer, A for admin ) as a list
Database tables used are login info, admin info, and cast info Login info = storing used id, password, and type of user Admininfo = storing all details of admin except password Custinfo = storing all details of the customer except password setUID() function sets the admin ID to store in database setCUID() function sets the customer ID to store in the database.
Admin.java
Functions include managing products (add,delete,view,search) by calling productsPage() function of products.java
Other functions include adding customers, removing customers, editing profiles, view registered customers.
For registering customers, since admin.java is subclass of Shop.java , registerCustomer() function of Shop is called by Shop.registerCustomer(), hence the small use of inheritance is here as the function need not be rewritten.
Customer.java :
Database table custinfo accessed for editing profile function
The main functions are viewing products, searching for products, adding and removing products from the cart, view the cart, and proceeding to the payment function.
Here first initializeProducts() function is called to store all product info in array lists, so that database need not be accessed everytime, hence Concept of collection framework is used here in form of ArrayList and through ArrayList functions .add(), .get(), .clear()
.add() = to add to ArrayList
.get(int i) = to get the element stored at index i in the ArrayList
Proceed to payment function calls payment.java class file and functions like add to cart, remove from the cart, and view cart call Cart.java. Calling is done via class objects like customerCart and p.
customerCart = object of Cart class p=object of Payment class
Customer.java is also the subclass of Shop.java where it calls the registerCustomer() function of the Shop.java through Classname.methodname like Shop.registerCustomer()
Products.java :
The main functions are added, removing, altering product info, viewing, and searching products setPid() function is used to set product id to store in the database
database table products are accessed to add, remove and alter product info
Cart.java :
This class file contains functions of the cart like add to cart, view cart, remove the product from the cart and cancel cart which is called from the customer.java class file via object.
Here add to cart function gets the product details to be added from customer.class via the constructor and adds them to the ArrayList so that the ArrayList can be used later on for displaying cart details and other functions as required.
Payment.java :
The main function of the payment class is to display bills and pay bills by calling bill.java, therefore it is an intermediate class between customer.java and bill.java and this class also stores payment details like bill and card details.
Bill.java :
Bill. class is called from the payment page through an object, this class contains details of a bill like a billing id, products purchased, and total amount. It also contains customer details whose bill it is. It stores the product details that are purchased in the ArrayList for easy access later on.
It contains functions like :
Generate bill = for calculating and storing the total amount in a variable Set bill id = for setting the bill id
Display bill = for displaying bill details
addtoDatabase = to add bill details to database table bills.
DatabaseConnection.java :
The database connection is a class file that is used to establish a connection with the MySQL server and to create a database “Onlineshop” and five tables – login info, admin info, bills, products, and cast info. It takes the help of a flag variable to check whether the database schema exists or not and if exists, it only connects Java to MySQL.
It is imported into the class files like Shop.java and products.java where it is used to access the database and make connections.
Exceptions that are used in the project are :
- IOException: This exception is used wherever BufferedReader has been used.
- For handling the exceptions caused due to database like
ClassNotFoundException or SQL Exception, a try-catch block has been added.
- For any other type of exception, sufficient try-catch blocks have been added.
Exception Handling features that are used in the project are :
Try-Catch block
Exception class functions like printStackTrace() have been used
throws keyword has been added in those methods wherever an exception is thrown and not handled by the method itself.
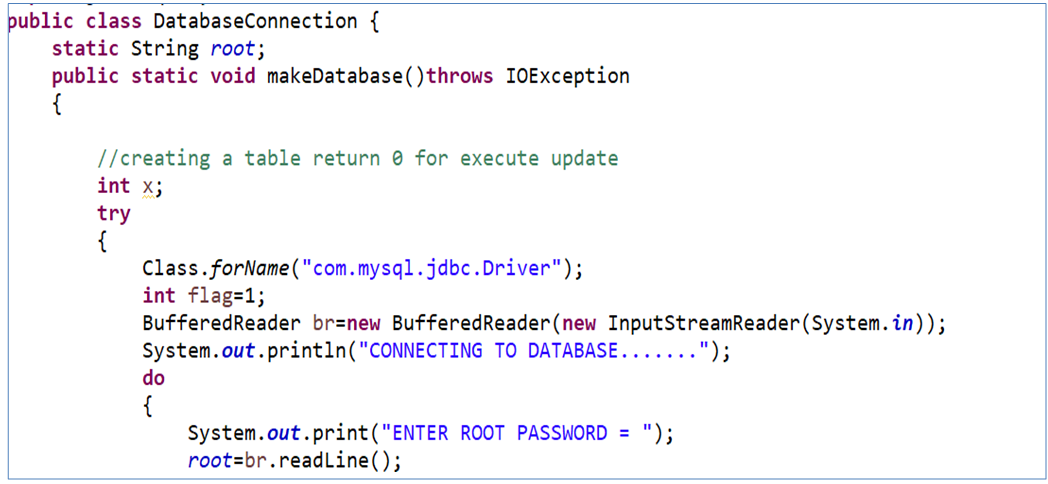
Snapshot of DatabaseConnection.java where Exception handling is used.
COLLECTION FRAMEWORK USED IN THE PROJECT
The concept of collections framework is used in the project through the implementation of ArrayList .
Use of ArrayList in the project :
Array List is used in the project to store the fetched results from the database for easy access later on. ArrayList is used in many class files in the project, like in customer.java , available product details are fetched from the database and stored in the ArrayList so that whenever the customer tries to access product info, it is fetched from the ArrayList and not from the database which reduces the complexity of code and saves time.
For using ArrayList Wrapper classes used are :
- Integer for storing integers
- Float for storing float values
- String as a class for storing String values
DATABASE SCHEMA USED IN THE PROJECT
Here, the concept of JDBC comes into the picture and is implemented using MySQL and JAVA. The database is used in the project for storing information about admins, customers, products, bills, and login details.
Database details are as follows :
Name of the database = Onlineshop
The tables used in the project are :
- Login Info Table
- Admin Info Table
- Cust Info Table
- Products Table
- Bills Table
How connectivity to MySQL was done :
To connect to the MySQL server, we have used the JDBC concept and used the SQL Driver class to connect to the MySQL database. For using the SQL Driver class and other classes used for connection, java.sql.* is imported into the java class file.
Creation of the database and creation of tables were made in the DatabaseConnection.java class file and to access the database, later on, the code written was :
Class.forName(“com.mysql.jdbc.Driver);
Connection con=DriverManager.getConnection(String URL,username,password);
SOME SNAPSHOTS OF PROJECT OUTPUT
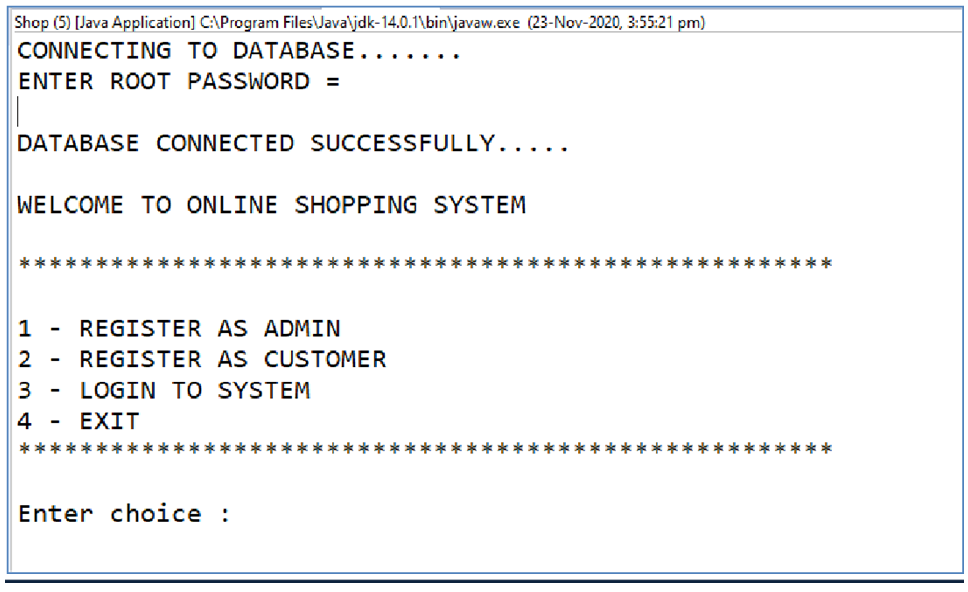
Main Page :
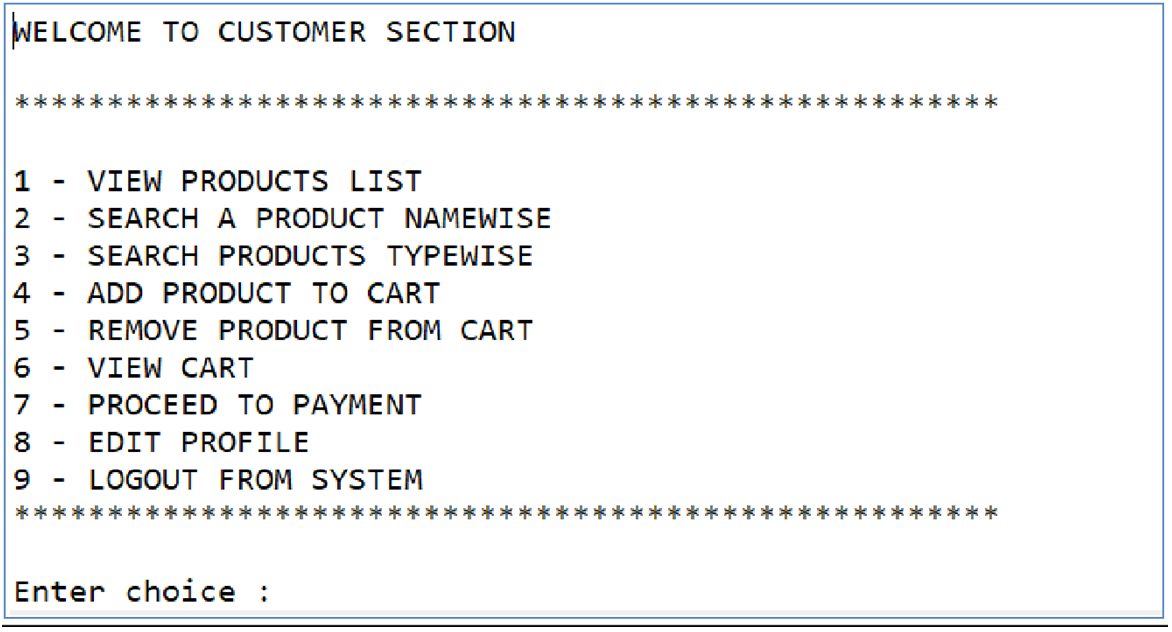
Customer section :
Some important points regarding the project :
- The connector jar file should be added to the “Java project” using :
JRE System Library > Build Path > Configure build path > Libraries > Add External JARs
- For connecting to the database used in the project, enter the root password of MySql
Download the Complete Java Console Application Project on Online Shopping Management System